Working with
Workflow
Adjusting
angular link routing
Configuring process steps and links
Additional
escalator properties
Adding
a new process attribute
Importing
process attributes from a resource
Adding
a new process table attribute
Deleting
a process table attribute
Editing
a process table attribute
Editing
a process table attribute column
Process attribute and table attribute column mapping
Configuring
an interactive activity
See also: Workflow Index
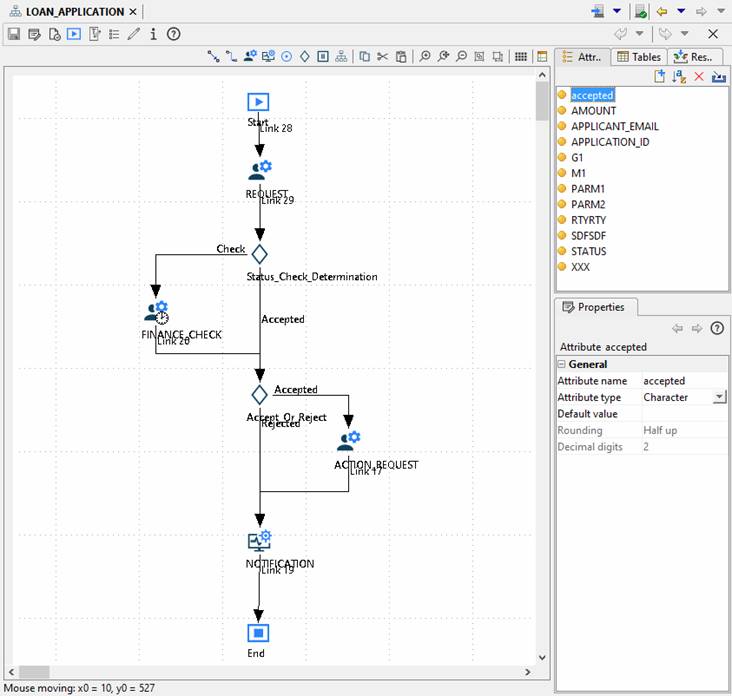
Viewing an existing process
An existing process can be opened by double clicking on the process name in the designer tree panel. This will display the process editor:
Creating a new process
Right click in the tree and select New > Workflow > Workflow Process. This will display a new process editor showing a start and end node on a drawing canvas.
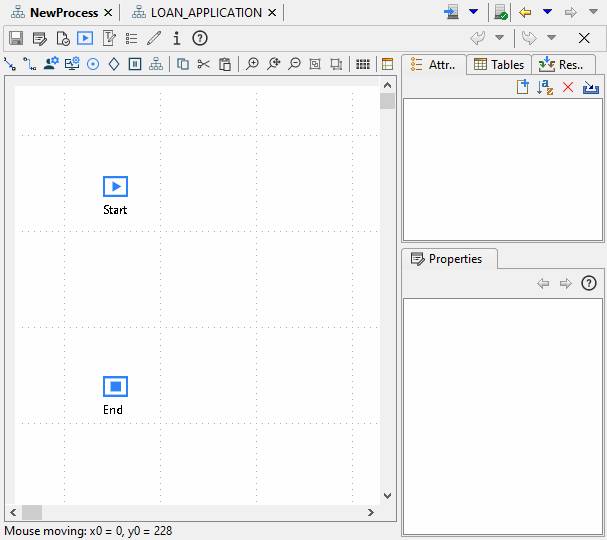
Adding process steps
To add a task node to the process, click one of the task icons
in the toolbar: Interactive task ![]() ,
or system task
,
or system task![]() .
The cursor will change to a hand
.
The cursor will change to a hand ![]() .
Move the mouse to the location where you wish to drop the task node and click
the mouse. This will place a task node icon on the drawing canvas.
.
Move the mouse to the location where you wish to drop the task node and click
the mouse. This will place a task node icon on the drawing canvas.
Similarly, to add a decision node click
the decision button ![]() on the toolbar, to add a split-join pair click
the split icon
on the toolbar, to add a split-join pair click
the split icon ![]() and to add a sub-process node click the
sub-process icon
and to add a sub-process node click the
sub-process icon ![]() .
.
Nodes can also be added using the Add… right-click menu.
When adding a split node, a join will automatically be added and its association with the split node will be visually indicated by a dashed line. This is to assist the designer in situations where there may be multiple split-join pairs in a single process. The join node may still be moved independently of the split but will always remain linked by the dashed line.
Once a node has been placed on the canvas it can be moved by selecting the node, holding down the mouse button and dragging it to the new location. When a node is selected, if the cursor is moved over it, it will change to the cross-hairs, move cursor to indicate that the node is movable.
Linking process steps
To link process steps, click either the direct ![]() or angular
or angular
![]() link icon. As for nodes, the cursor will turn
into a hand to indicate that you are in add mode. In the case of links, when the hand hovers over a
node, four blue, link-attachment points will be highlighted around the edges of
the node.
link icon. As for nodes, the cursor will turn
into a hand to indicate that you are in add mode. In the case of links, when the hand hovers over a
node, four blue, link-attachment points will be highlighted around the edges of
the node.
![]()
Angular links
To create angular (or rectilinear) links, select the angular link toolbar button or use the (Add -> Add angular link) right-click menu option. Once the cursor changes to a hand, move it over your start node, press and hold the mouse button over one of the blue attachment points and drag the mouse to the destination node. While dragging the mouse, a dashed line will appear to show the direct route of the line. Finally, release the mouse button over the attachment point on the destination node. For angular lines, the link will route itself using horizontal and vertical lines to reach the selected destination attachment point in the optimal way. The link will retain it’s attachment to the selected attachment points regardless of where the nodes are moved relative to each other.
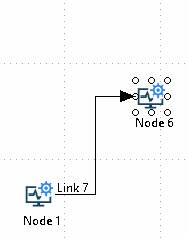
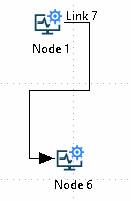
Direct links
Direct links are created as for angular links but, in this case, once the direct link button has been clicked on the toolbar or the (Add -> Add direct link) option has been selected from the right-click menu, it is sufficient just to select anywhere in the start node and drag to anywhere in the end node since the attachment points are automatically selected based on the relative positions of the two nodes.
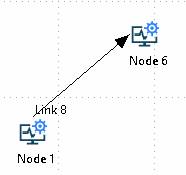
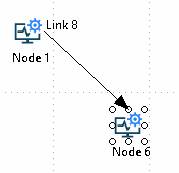
Detached links
In both cases, if a link becomes detached from a node, the detached end will turn red.
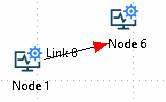
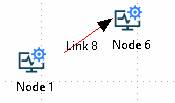
Changing link type
Links may be changed from direct to angular using the right-click menu option (Link -> Set link angular) or (Link -> Set link direct)
Adjusting angular link routing
The routing of angular links may be adjusted by clicking on the blue diamond line adjuster and dragging it to the desired position.
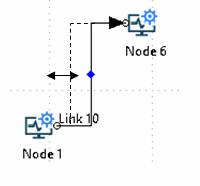
Note: Since angular links are automatically routed, if the node at one or both ends of an angular link are moved, the optimal routing will be recomputed and hence any manual adjustment will be lost.
Link label positioning
The position of the link label can be set
to be either the start or end of both link types. For direct links, the label
may also be positioned in the middle of the link. The label position is set
using the right-click link menu options: (Link.. -> Label link at start), (Link… -> Label link at end) and (Link… -> Label link in the middle)
Other general editing
The process designer is based upon a standard, free-layout canvas supporting the following functionality:
Rubber-band selection
A group of nodes and links can be selected by drawing a rubber-band around the items to be selected. To do this, press the mouse button in the start position of the rubber-band and begin dragging the mouse across the canvas. A dashed box will appear. Drag the mouse so that the dashed box encloses the objects you wish to select and release the mouse button.
Selected objects will be highlighted with small circles at their extremities.
Multi-selection
A group of nodes and links can also be selected by selecting the first object as usual and then using Ctrl-click to add more objects to the selection. Using Ctrl click on an object which is already in the selection removes that object from the selection.
This mode can be used interchangeably with rubber-band selection.
Cut, Copy and Paste
Nodes and links can be cut, copied and
pasted using either the toolbar buttons (copy![]() , cut
, cut ![]() ,
paste
,
paste ![]() ),
the right-click menu options or the keyboard shortcuts: Ctrl C for copy, Ctrl X for
cut and Ctrl V for paste.
),
the right-click menu options or the keyboard shortcuts: Ctrl C for copy, Ctrl X for
cut and Ctrl V for paste.
Alignment
Nodes on the page can be aligned using the alignment operations available on the right-click menu:
![]() Align top
Align top
![]() Align bottom
Align bottom
![]() Align left
Align left
![]() Align right
Align right
![]() Align centres
horizontally
Align centres
horizontally
![]() Align centres vertically
Align centres vertically
For example, to align nodes in a vertical line, select the nodes you wish to align, click the right mouse button to bring up the right-click menu and select (Align… -> Align centres vertically). The first node selected in a multi-selection will be used as the reference node, i.e. The one to which the others will be aligned.
Note: When selecting nodes and links using rubber-banding and
applying an alignment operation, the alignment will only be applied to the
nodes in the selection since link routes are calculated automatically.
Grouping
Objects on the page can be grouped using
the group ![]() and ungroup
and ungroup ![]() buttons on the toolbar. A group of objects can
then be manipulated as a single entity.
buttons on the toolbar. A group of objects can
then be manipulated as a single entity.
Ordering
Ordering is useful in the case where objects overlay in a drawing. For example, if a link crosses a node and it is not possible to lay the process out in such a way that this does not happen, it may be the case that the node is on top of the link which makes it look like the link is attached to the node. To make this clearer you can select the link and then choose (Order -> Bring to front) from the right-click menu. This will bring the link to the front, i.e. on top of the node. Alternatively, you could select the node and choose (Order -> Sent to back) which will have the same ultimate result.
Tool Tips
Hovering over any node in the process will display a tool tip message containing all the configuration information for that node.
Undo and Redo
Changes can be undone and redone using
either the toolbar buttons (undo ![]() and redo
and redo ![]() )
or using the standard keyboard shortcuts: Ctrl
Z for undo and Ctrl Y for redo.
)
or using the standard keyboard shortcuts: Ctrl
Z for undo and Ctrl Y for redo.
Zoom
The canvas view can be zoomed in and out
using the toolbar zoom buttons: zoom out ![]() , zoom in
, zoom in ![]() and actual size
and actual size ![]() .
.
Grid
The canvas has a background grid which can
be shown or hidden using the grid configuration dialog. To access this, click
on the ![]() icon on the toolbar. The grid also supports
snap-to-grid which means that objects placed on the page will automatically
jump to the nearest grid location. This assists alignment. Snap-to-grid and
grid resolution can also be configured using the grid configuration dialog.
icon on the toolbar. The grid also supports
snap-to-grid which means that objects placed on the page will automatically
jump to the nearest grid location. This assists alignment. Snap-to-grid and
grid resolution can also be configured using the grid configuration dialog.
Configuring process steps and links
The process start and end nodes have no configurable attributes. They are present purely to ensure that the start and end of the process are clearly defined. These are used during the validation process.
Double clicking on any node in the process will display the node’s configuration dialog. Each type of node supports a slightly different set of configuration attributes and these are described below. The only common attribute for all nodes and links is the name attribute. This is the name which will be displayed in the designer and which will be used if the node or link is to be referred to from within a script. In most cases is not mandatory to provide a name since if not supplied, it will default to “Node n” or “Link n” where n is the node or link number. The only case where a non-default name is mandatory is for links leaving a decision node since these are used in the decision script to identify the $NEXT_STEP. In this case the existence and uniqueness of these names will be checked during the validation process.
Configuring a task node
The task node configuration dialog presents four tabs. Only the first (General) tab is applicable when the task is associated with a system activity. All four are applicable when the task is associated with an interactive activity. The contents of the tabs are described below:
General configuration
This tab presents the following attributes in addition to the task name:
· Description – This is a textual description of this task. It may be presented in client applications when displaying enactment details. This description may contain references to process attributes which will be substituted at runtime when values for those process attributes are available. For example:
Finance
check for &&APPLICANT_NAME for loan of &&AMOUNT pounds
Where APPLICANT_NAME and
AMOUNT are both process attributes. This will result in descriptions
generated for specific enactments of this task of the form:
Finance
check for Margaret Smith for loan of 4,000 pounds
Finance
check for Bernard Jones for loan of 22,500 pounds
This description text will be
displayed in this dialog in the designer’s default language. Alternative
language texts can be set up using the multi-lingual
texts configuration dialog.
· Activity – This is the activity which will be associated with this task. Click the … button to select an activity.
· Priority – This is the priority to be associated with this task.
· Task cancellable – This defines whether the task can be cancelled. The default for this is yes.
Mappings
This tab is only available for interactive tasks. It displays the input and output parameters as defined on the activity associated with this task and allows the designer to map those parameters to process attributes. These mappings will be used to automatically pass in the selected process attribute values to the activity on initialization and set the selected process attribute values on completion of the activity.
Resources
This tab is only available for interactive tasks. It defines the resource allocation rules for enactments of the task being configured. It presents a selection of assignment modes, only one of which must be chosen. The modes are as follows:
· Public – this is a non-authenticated assignment mode. It may only be used for the first task in any process and represents, say an application form submitted by a member of the general public.
· Job opener – this automatically assigns the task to the same resource who opened the job. Care should be taken to ensure that the job opener is an authenticated user. If the job opener is unauthenticated e.g. a member of the public on an open web site, then job opener will have a null value and an attempt to assign a subsequent task to the job opener will cause a runtime error.
· Resource from previous task – this automatically assigns the task to the same individual who completed the selected previous task. The task name should be selected from the adjacent drop-down menu.
· Process attribute – this automatically assigns the task to a resource named in a process attribute. The process attribute name should be selected from the adjacent drop-down menu.
· Named resource – this automatically assigns the task to the resource name as supplied in adjacent field.
· Follow-on task – this automatically assigns the task to the resource who completed the previous task in the same stream.
· Custom – this enables the custom assignment expression panel below and will assign the task either to an individual resource or to a pool of resources as determined by the configured assignment handler. When using the default assignment handler, this panel contains one field Assignment key and this value will be passed to the Assignment Handler System Service. Click here for more details.
The default resource assignment mode is Job opener.
Security
This tab is only available for interactive tasks. It defines the security constraints which will be placed on this task. It controls who is allowed to access, execute or modify this task and to what degree.
Configuring a decision node
A decision node has only one configurable attribute in addition to the
decision node name:
Decision script – This is a script that can be written using any supported server-side language. The only compulsory element of a decision script is that it sets the $NEXT_STEP system variable to the name of the link to be followed as a result of the decision, for example:
|
FPL: |
API based language
(Javascript): |
|
if [ AMOUNT > 1000 ] set
$NEXT_STEP = 'Check'; else set
$NEXT_STEP = 'Accepted'; endif |
if ( fields.AMOUNT.value
> 1000 ) { system.variables.$NEXT_STEP.value = "Check"; } else { system.variables.$NEXT_STEP.value = "Accepted"; } |
Where AMOUNT
is a process attribute.
Configuring a split-join pair
A split-join pair is controlled by the split. If the split is deleted, so is the corresponding join. No actions can be performed on the join in isolation other than moving it. If a split is copied, so is the join.
Splits have no additional configurable attributes other than the name.
Configuring a pause node
The properties of a pause node are shown below:
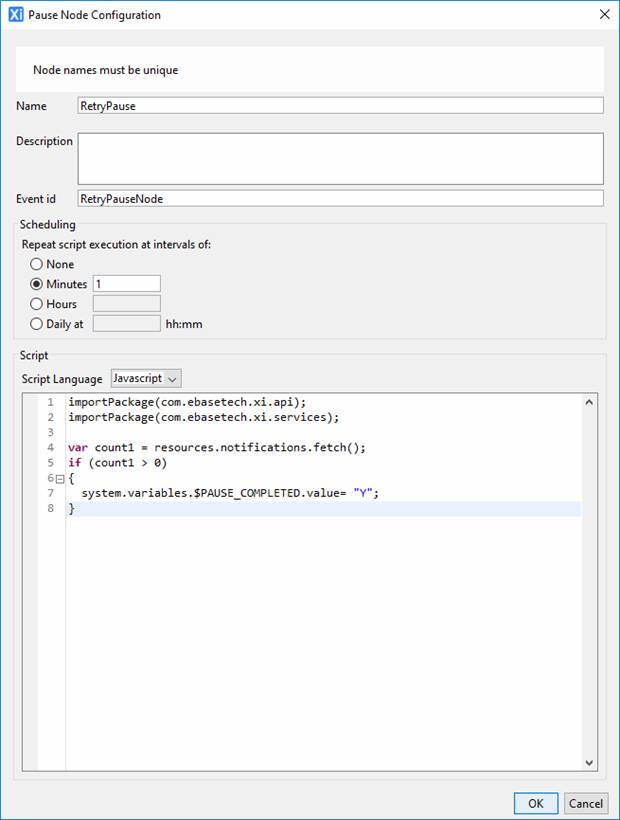
· Name: the node name - as for all nodes
· Description: the node description
· Event id: the id used in a workflow post command to identify this Pause Node. An event id is only required when the workflow post command is used. When specified, event ids must be unique within each workflow process.
· Scheduling: specify the interval at which the script is executed. If None is specified, the script will be executed only as a result of a workflow post command.
· Script: the script executed at the scheduling interval or as a result of a workflow post command. If the script sets system variable $PAUSE_COMPLETED to value 'Y', the pause node will complete.
See Pause Node for more information.
Configuring a sub-process
In addition to the node name, a sub process configuration dialog also requires the following configuration:
· Sub-process – This is the process for which a job will be opened when this node is reached. Click the … button to select a process.
· Input Parameters – This lists the process’s defined input parameters and allows the designer to map process attributes from the current process to these input parameters. This will be used to pass the values of these process attributes into the process as its initial input parameters.
· Output parameters – As for the input parameters, this lists the process’s defined output parameters and allows the designer to map them to process attributes as defined on the current process. When the sub-process completes, the values of its output parameters will be set on the mapped process attributes in the parent process.
Configuring a link
The only configuration on a link is its name. This is only mandatory in the case where the link is an out-link from a decision node. The names of these links will be used when defining the next step in the decision logic.
Adding escalations
To add an escalator to a process node, right-click on the node and select Edit escalators. This will display the escalator editor dialog:
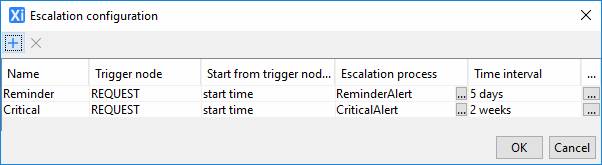
Each row in this dialog represents one escalator. These can be added and removed using the add and delete icons.
If a process node has escalators associated with it, its node icon will be augmented with a clock as shown above.
Basic escalator properties
Each escalator has the following properties which need to be set:
· Name – The name of the escalator which will appear on the task list.
· Trigger node – the process node whose start or completion will trigger the escalator’s timer to start ticking.
· Start from trigger node’s… - whether it should be the start or completion of the trigger node that starts the escalator’s timer ticking.
·
Escalation
process – The process to run when the escalator’s timer expires (provided
the escalated process hasn’t been completed yet).
·
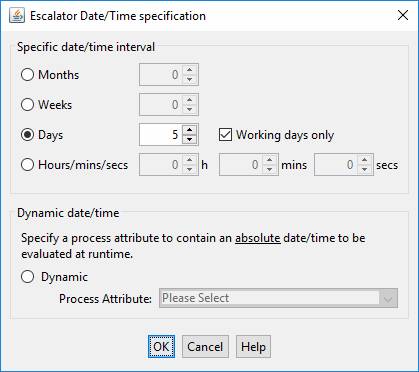
When option Dynamic is selected, the time at which the escalator should fire is determined dynamically from the selected process attribute. The selected process attribute must have a type of either DATE, DATETIME or TIME and only process attributes of these types are shown in the dropdown list. The value of the process attribute could be set in a number of ways according to the processing required e.g. set using a system task, passed as a parameter from an interactive task, passed as a parameter when the job was created, read from a database etc. The following table shows how the time at which the escalator should fire is determined for each process attribute type:
|
DATE |
Set to midnight (time 00:00)
on the specified day. If the date is the current date or is in the past, the
escalator will fire immediately. |
|
DATETIME |
Set to the specified date and time. If this is in the past, the escalator will fire immediately. |
|
TIME |
Set to the next occurrence of the specified time. e.g. if the current time is 16:00 and the attribute contains 10:00, this is interpreted as 10:00 on the following day. |
If the process attribute has no value, the escalator fires immediately.
Note: the value of the process attribute is determined when the escalator is triggered i.e. at the start or completion time of the trigger node. Once the escalator has been triggered, the time interval cannot be changed. When an escalator is triggered at the start time of an interactive node, it is not possible to pass the time interval value as a parameter into the same interactive task – this is because escalators are enacted before parameters are received.
Additional escalator properties
These are displayed by clicking the “…” button at the end of each escalator row in the table. The dialog which is displayed offers three tabs:
Description: This allows a description to be provided for this escalator. This text can be used to help identify a particular instance of an escalation when it appears on, for example, someone’s task list. The description text may include process variables for substitution (as for process node description text).
Resources: In order for the escalator to be
displayed on someone’s task list while it is ticking, it must have a resource
assignment criteria associated with it. This is done in the “Escalator
additional properties” dialog.
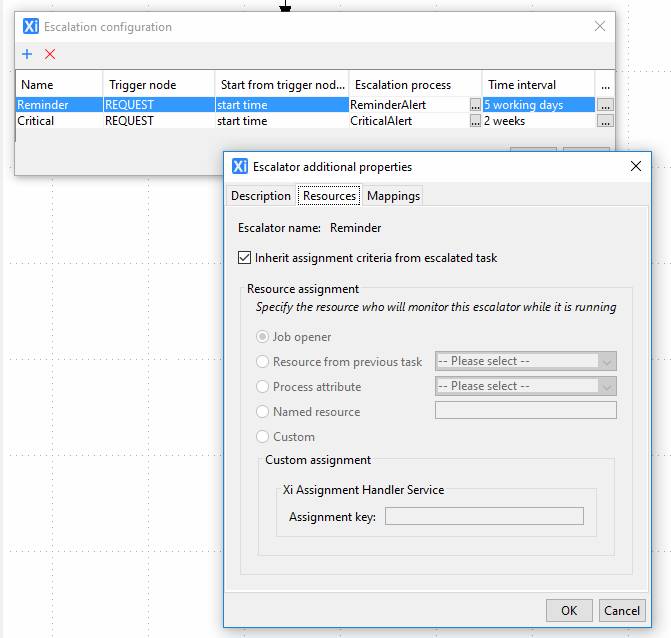
In the case where the escalated node is an interactive task which already has its own assignment criteria configured, by default, the assignment criteria for the escalator is inherited from the escalated task. This means that the person who is due to perform the escalated task will also see the escalator sitting in their task list which should also act as a reminder that the task will be due soon. If the task has a group assignment, the escalator task list entry will be visible to all members of the group.
In the case where either the escalated node is not an interactive task or if the escalator is to appear on, say the task list belonging to the manager of the person to whom an interactive task is assigned, this can be configured by setting an explicit assignment criteria on the escalator using this dialog (in the same way as assignments are set for interactive tasks, see Resources).
If an escalator is assigned to a group, the escalator task list entry will be visible to all members of the group.
Mappings: This tab allows the mapping of any input and output parameters for the escalation process in the same way as is done for sub-processes. Any input or output parameters which are defined in the escalation process will automatically be presented in this tab, ready for mapping.
Process properties
Process properties are configured by
clicking the ![]() button on the top toolbar in the process
editor. This displays the process properties dialog which enables the designer
to configure the following:
button on the top toolbar in the process
editor. This displays the process properties dialog which enables the designer
to configure the following:
General
· Description – This is a textual description of this process. It should contain enough information so as to be useful when displayed in a client application when, say, referring to an active job. The text may contain substitutable text in the same way as task description which will be populated at runtime. For example:
Loan application id &&APPLICATION_ID
for &&APPLICANT_NAME requesting a loan of &&AMOUNT pounds
Where APPLICATION_ID. APPLICANT_NAME and AMOUNT are process attributes.
This description text will be displayed in this dialog using the designer’s default language. Alternative language texts can be set up using the multi-lingual texts configuration dialog.
· Process creator – This is a read-only field and shows the id of the designer who created this process.
· Process owner - This is the id of the individual who is ultimately responsible for this process.
·
Error
recovery process – This is a separate process which will be run in the case
of a failure during the running of this process. Typically the error recovery
process will be a very simple process which notifies someone that something has
gone wrong, for example, by sending an email. The error recovery process can
either be selected from the drop-down menu which shows the existing set of
processes, or a new process can be created by clicking the new process button to the right of the drop-down menu.
It is expected that there will be one individual in the organization who is responsible for maintaining the workflow system and it would be sensible to design the error recovery process so that it sends an email to that individual to let them know an error has occurred. See also Workfow configuration for details on setting up the primary error recovery email address.
Job owner assignment
The job owner is the person ultimately responsible for a particular job. As described in the Workflow Concepts document, job ownership can be assigned in two different ways. The job owner may be statically assigned to a named individual when the job is opened in which case the ownership persists throughout the life of the job. Alternatively, the job may be dynamically assigned. This is configured using this Job owner assignment tab. If dynamic assignment is required, the Enable dynamic assignment of job owner check box should be checked. This in turn enables the assignment expression panel which is the same panel defined by your organization for specifying resource assignment for tasks. Once configured, this assignment definition will be used to dynamically determine the current owner of the job.
Security
This tab defines the security constraints for jobs opened on this process. It controls who is allowed to access, execute or modify jobs and to what degree.
Resources
Any resources used by the workflow process must be added to the Resources View before they can be used. Once added, process attributes can be mapped to resource fields and table columns, and the resources can be used by scripting statements.
Process attributes
Process attributes are analogous to
regular Ebase Xi form fields. The process attributes are shown in the Attributes view tab as shown below:
A process attribute is a very simple version of an Ebase Xi form field. It has a
name, a data type and a default value. Process attributes can be added,
imported and edited in exactly the same way as Ebase Xi form fields.
They should be thought of as holders of data. Any data that needs to be stored, calculated or passed around in a process will be held in a process attribute.
Process attribute data is passed into and out of activities via activity input and output parameter mappings.
Process attribute data is passed into and out of sub-processes via sub-process input and output parameter mappings.
Process attribute data is manipulated directly in System activity scripts and in decision scripts.
Adding a new process attribute
To add a new process attribute, click the ![]() icon on the process attributes toolbar. This will
add a blank row in the table. You can type the name of the fields in the name
column. Additional properties of the process attribute can then be set in the
Properties View.
icon on the process attributes toolbar. This will
add a blank row in the table. You can type the name of the fields in the name
column. Additional properties of the process attribute can then be set in the
Properties View.
Deleting a process attribute
To delete one or more process attributes,
select them from the table (using Shift
click to select a range or Ctrl click
to add individual attributes to the selection) and then either click the ![]() button on the process attribute toolbar or
select Delete from the right-click
menu.
button on the process attribute toolbar or
select Delete from the right-click
menu.
Editing a process attribute
When a process attribute is selected in the Attributes view tab, all of its properties are displayed in the Properties view tab. These can be edited as required and will be saved when the process is saved.
Importing process attributes from a resource
Process attributes can be imported from
resources in the Resources View. Attributes
imported in this way are automatically mapped to the resource fields and can be
used in scripts in exactly the same way as form fields to fetch, manipulate and
store data from the resources. To import process attributes, click the ![]() icon on the process attributes toolbar. This
will bring up the Import from external
resource dialog box.
icon on the process attributes toolbar. This
will bring up the Import from external
resource dialog box.
![]() It is
not possible to use this dialog to import from a Database Resource with the For use with table operations option
checked. When this option is checked, the resource can only be used with a
table and the resource fields can only be imported as table columns.
It is
not possible to use this dialog to import from a Database Resource with the For use with table operations option
checked. When this option is checked, the resource can only be used with a
table and the resource fields can only be imported as table columns.
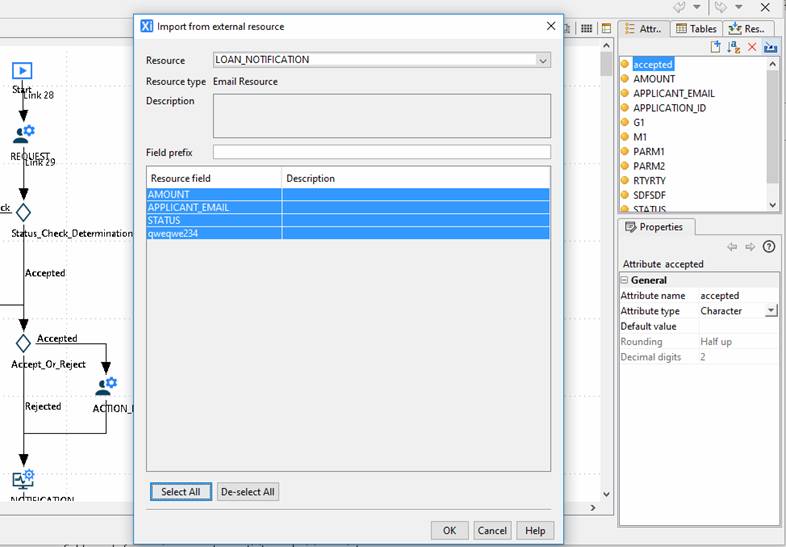
From the Resource drop-down menu, select the resource which you’d like to import from. The selected resource’s fields will be displayed in the table below. Select the fields you’d like to import and click OK. Process attributes will automatically be created for each of these resource fields. Each process attribute will also be automatically mapped to the corresponding resource field, ready for use in any system activity or decision script.
If manual process attribute mapping is required, it can be done using the Process attribute mapping dialog.
Process Table Attributes
Process table attributes are analogous to
regular Ebase Xi table fields. Process table attributes are shown in the Tables view tab as shown below:
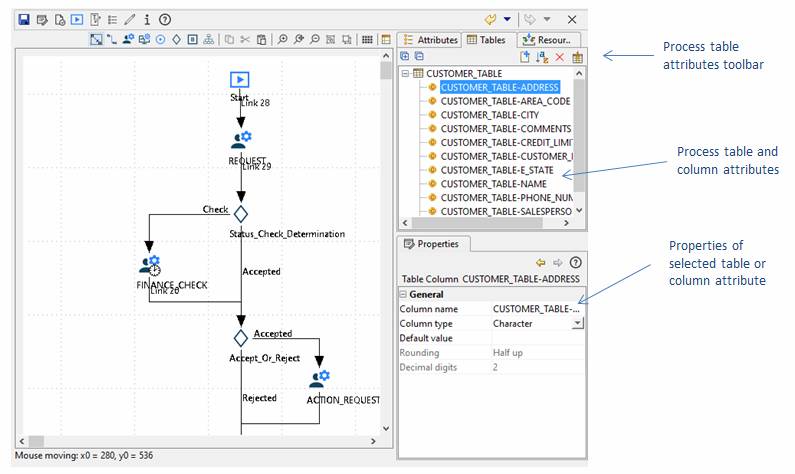
A process table attribute is a very simple version of an Ebase Xi table. Its
columns have a name, a data type and a default value. Process table attributes
can be added, imported and edited in exactly the same way as Ebase Xi form
tables.
They should be thought of as holders of tabular data. Any tabular data that needs to be stored, calculated or passed around in a process will be held in a process table attribute.
Process attribute data is passed into and out of sub-processes via sub-process input and output parameter mappings. This is done at the table level only. The table in the parent process and the table in the sub-process must have the same set of columns defined on them.
Process table attribute data is manipulated directly in System activity scripts and in decision scripts.
Adding a new process table attribute
To add a new process table attribute,
click the ![]() icon on the process table attributes toolbar.
This will display the New table dialog box. For details see Tables View.
icon on the process table attributes toolbar.
This will display the New table dialog box. For details see Tables View.
Deleting a process table attribute
To delete one or more process table
attributes or table attribute columns, select them from the view and then
either click the ![]() button on the process attribute toolbar or
select Delete from the right-click
menu.
button on the process attribute toolbar or
select Delete from the right-click
menu.
Editing a process table attribute
When a process table attribute is selected in the Tables view tab, all of its properties are displayed in the Properties view tab. These can be edited as required and will be saved when the process is saved.
Editing a process table attribute column
When a process table attribute column is selected in the Tables view tab, all of it’ properties are displayed in the Properties view tab. These can be edited as required and will be saved when the process is saved.
Process attribute and table attribute column mapping
The process attribute mapping dialog
allows the designer to view and modify the mappings between process attributes
and resource fields. To display this dialog, select a resource in the Resources
View, then click the ![]() button at the top of this panel.
button at the top of this panel.
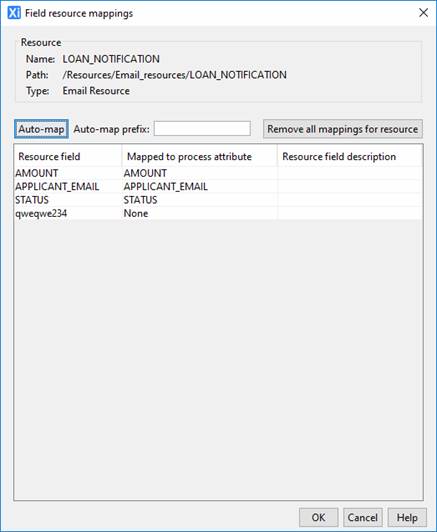
Mapping can be edited by selecting a process attribute for each resource field you wish to map into your process.
Resources with repeating fields can be mapped to process table attribute columns in the same way as can be done for table fields in Ebase Xi forms.
Clicking the Auto-map button will make a best-effort to map attributes to fields of the same name. If provided, the Auto-map prefix will be used to allow, say table columns, to be mapped to repeating fields in the resource. For example, if the prefix “USERS-“ is provided, this will automatically map a resource field called ID to the table column field USERS-ID.
Clicking Remove all mappings for resource will reset all mappings to None.
Multi-lingual texts
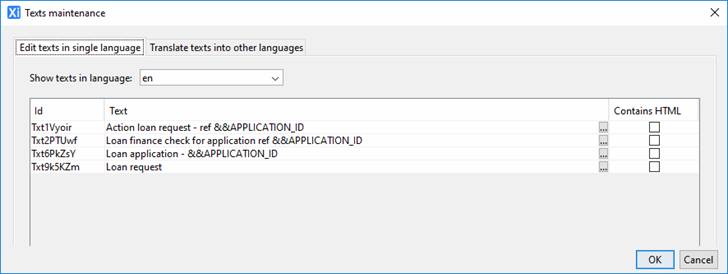
Process and task descriptions support
multilingual texts. The text presented in the main edit dialogs for each of these
will be in the designer’s default language (as configured in the Designer Preferences) however
the texts may be translated into any language using the texts maintenance
dialog which is accessed by clicking the ![]() icon on the toolbar at the top of the editor
panel.
icon on the toolbar at the top of the editor
panel.
Input and output parameters
Process attributes and process table attributes can be identified as process input or output parameters. This is relevant in the case where a process is acting as a sub-process and the input and output parameters are used for passing data between a sub-process and its parent.
In order to define the input and output
parameters, click the ![]() icon on the toolbar at the top of the editor
panel. This will display the process
parameters dialog which allows you to select process attributes and process
table attributes from the existing list and add them to either the list of
input or output parameters.
icon on the toolbar at the top of the editor
panel. This will display the process
parameters dialog which allows you to select process attributes and process
table attributes from the existing list and add them to either the list of
input or output parameters.
Designer Note
A textual designer note may be added
to the process. This is stored with the process and acts as a note-pad to assist the designer during
the design process. The designer note is displayed by clicking the ![]() button on the toolbar at the top of the editor
panel. This displays a dialog containing a simple text area into which free
text may be entered.
button on the toolbar at the top of the editor
panel. This displays a dialog containing a simple text area into which free
text may be entered.
Validation
Once the process has been designed, it is
necessary to check that it is valid according to the rules as described in Process Structure. This can be
done at any time during the design process by clicking the validate ![]() icon on the toolbar at the top of the editor
panel. This will perform a full validation check on the process and display the
results in the Validation Results
view tab as follows:
icon on the toolbar at the top of the editor
panel. This will perform a full validation check on the process and display the
results in the Validation Results
view tab as follows:
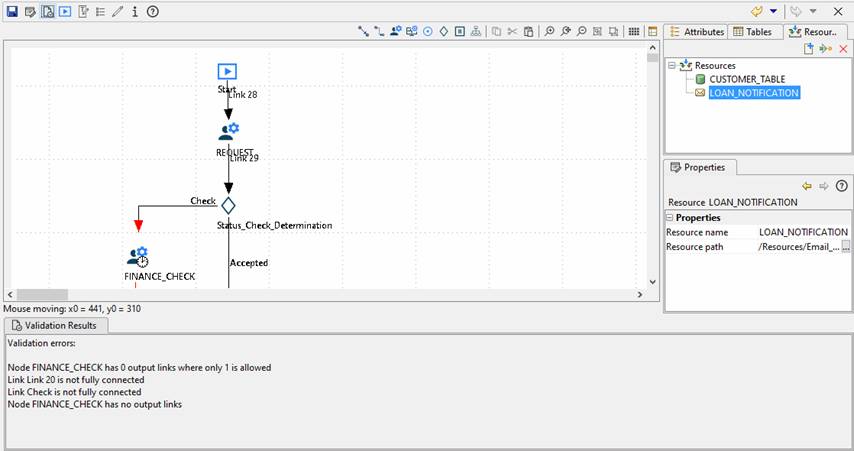
This view may be hidden but will be automatically displayed if any validation errors are found.
If validation is successful, the message “No problems found” will be displayed.
It is perfectly acceptable, during development, to save processes in an invalid state.
Testing
In order to test the flow of a process, a process test stepper is provided. This
allows the designer to step through the process setting attribute values and
selecting completion states at each step to ensure that all routes through the
process behave as expected. The process test stepper is launched by clicking
the ![]() icon on the toolbar at the top of the editor
panel. Before launching the stepper itself, an initialization dialog is
presented which allows you to enter the following startup
information:
icon on the toolbar at the top of the editor
panel. Before launching the stepper itself, an initialization dialog is
presented which allows you to enter the following startup
information:
· the language to execute in
· the job opener user name
· values for any process input parameters
Once OK has been clicked, the process test stepper is displayed:
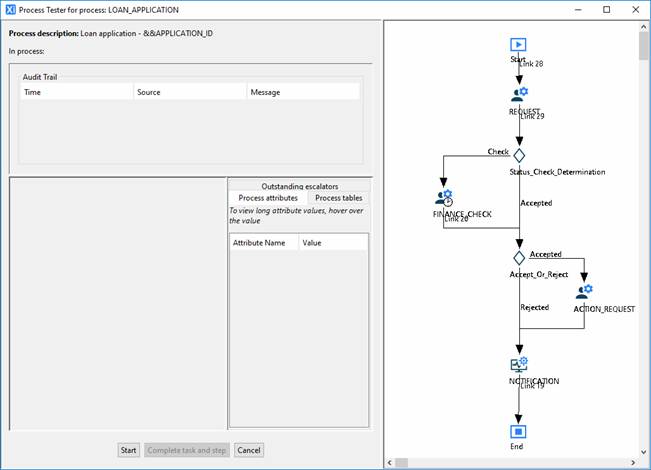
At this point a job has not yet been opened for this process. The process description text is displayed across the top of the stepper but since there is no job opened and hence no process attribute values populated, the substitutable texts will appear as the raw attribute name references.
To open a job for the process, click the Start button.
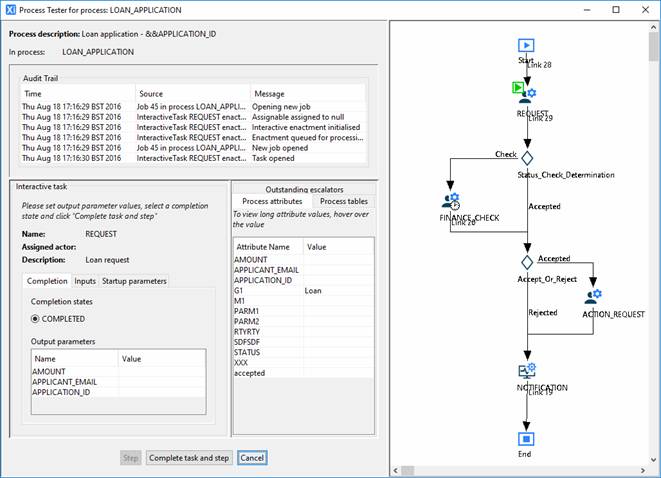
A job is opened for this process and the
first task node is highlighted in the process diagram as being the running node
by a ![]() icon.
icon.
The attributes of the first task enactment are presented in the bottom left-hand panel. In this example, the first task is an interactive task. As the tester, you are now required to enter any output parameter values, select a completion state and click the Complete task and step button at the bottom. The Input and startup parameter values supplied to this task enactment are presented on tabs in this section of the stepper simply for information.
The right-hand bottom panel displays three tabs:
· Process attributes: shows the current state of the process attributes. After each process step, these values are updated to reflect any changes that happened during that step. These are read-only and are provided to aid the tracking of the process.
· Process tables: same as process attributes but show the state of any tables
· Outstanding escalators: shows any escalators which have been triggered but whose escalated node has not yet been completed (see Testing escalations).
The top panel displays the audit trail for this job. This is made up of three parts:
· Time - The timestamp for when the log was created
· Source - A textual description of the object in the process for which this log record has been generated.
· Message – the audit log message describing what was done.
·
In this example, clicking Complete task and step takes the job onto the next step which, in this case, is a decision step:
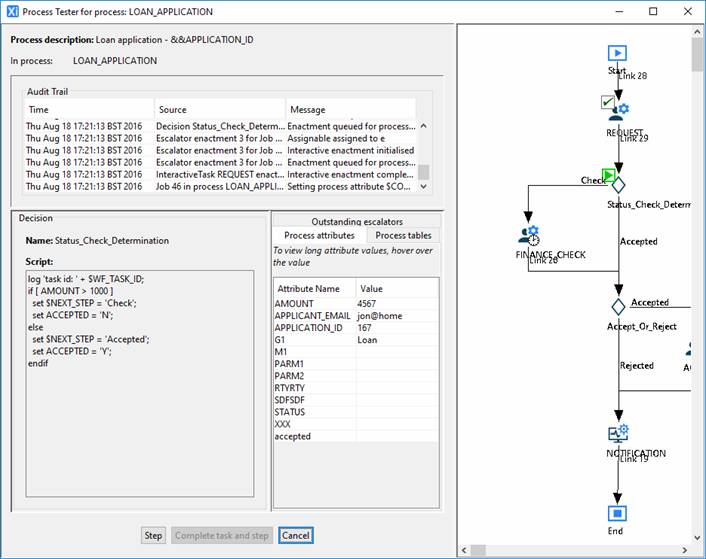
In the process diagram, the REQUEST task
is now marked as completed with a ![]() icon. The current step is now the decision
which is indicated with the
icon. The current step is now the decision
which is indicated with the ![]() icon.
icon.
The test stepper just displays the decision script (for reference) in the bottom left-hand area. Note that the entered AMOUNT from the previous step has been set on the AMOUNT process attribute on the right-hand side. This is because the activity output parameter named AMOUNT has been mapped to the process attribute also (coincidentally) named AMOUNT (and similarly for the APPLICANT_EMAIL and APPLICATION_ID).
Clicking the Step button causes the decision script to be executed and the next process step to be queued up for enactment. In this case, the next step is another interactive task, FINANCE_CHECK. This task is assignable to any resource in the Loans department. Since there is a choice for the assignment, the test stepper presents a choice dialog to allow you to select which user to assign the task enactment to:
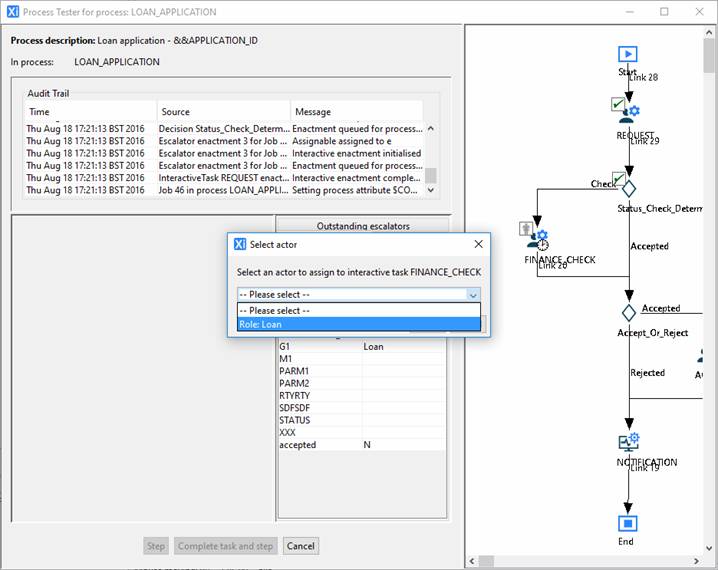
Selecting a resource and clicking Ok will display the next task enactment.
Before the task is assigned, it is marked
with the ![]() icon. Once Ok has been clicked and the task
has been assigned, it is marked with the
icon. Once Ok has been clicked and the task
has been assigned, it is marked with the ![]() icon.
icon.
At any point, the designer may cancel the process in which case it will be transitioned to the cancelled state and the test stepper will close. The designer is also at liberty, at any time, to enter invalid data in which case it is most likely that an error message will be displayed and the process will be marked as failed. The Cancel button will change to say Close (failed job) to indicate that the job can not proceed. Clicking this will close the stepper.
Multiple jobs may be run in parallel. This is done simply by starting test stepper sessions before others have completed. If the process designer for a given process is closed, all open test stepper sessions for that process will also be closed.
Note: Jobs opened by the test stepper are maintained separately from live jobs on released processes. Jobs run in the test stepper will not be visible in the task list application or in the workflow administration application.
Once you have successfully stepped through to the end of the job, the right-hand button will say Finished. Clicking this will close the test stepper.
Testing sub-processes
In an example where a process called LOAN_APPLICATION has a sub-process called LOAN_APPROVAL, when the stepping has reached the LOAN_APPROVAL sub-process node, the next click of the Step button will open a job for the LOAN_APPROVAL sub-process and step into it. The display will change to show the job context of the LOAN_APPROVAL job. The LOAN_APPROVAL process diagram will be displayed along with its process attributes and escalators. The In process “breadcrumbs” at the top of the dialog will show the nested status of the jobs being run. In this example it will show LOAN_APPLICATION -> LOAN_APPROVAL.
Once the LOAN_APPROVAL job has been stepped through to completion, the test stepper will return to the LOAN_APPLICATION job with its context updated to reflect any changes which were caused by the sub-process and the In process breadcrumbs will show just LOAN_APPLICATION.
Testing escalations
The test stepper allows escalators to be tested in non-real-time to allow verification of their functionality independent of timing issues.
The list of the next escalators available to fire is presented in the tab behind the process attributes tab:
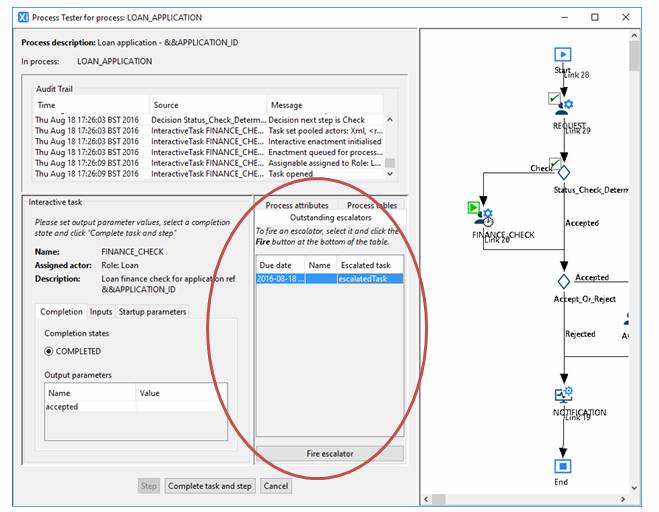
If a node has more than one escalator, only the one with the shortest escalation time interval is shown in the list. Once that one has been manually fired, the one with the next shortest interval will be displayed in the list and so on.
In order to fire an escalator, select it from the list and click the Fire escalator button.
This will cause the test stepper to step into the escalation process as follows:
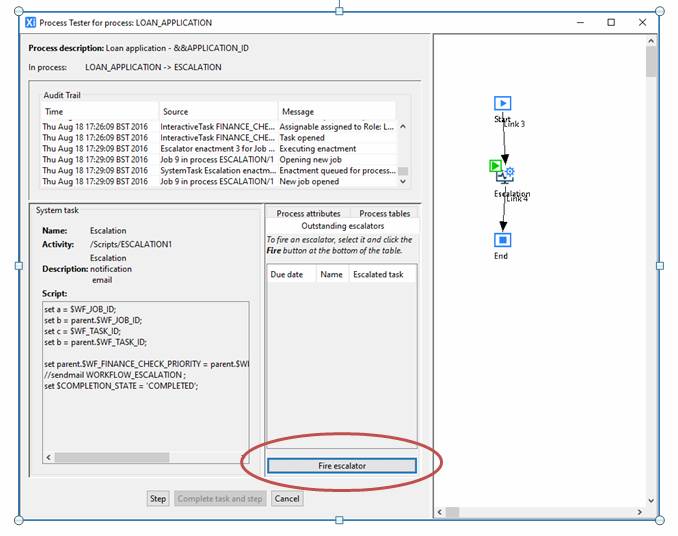
In this example, this is a simple process which contains a single task which increments the parent task’s priority.
Note that the In process breadcrumbs at the top of the test stepper dialog show the current state of jobs being run as: LOAN_APPLICATION -> DO_ESCALATION. This means that we are currently in a job for process DO_ESCALATION (just as it would be if DO_ESCALATION were a simple sub-process).
Stepping through this escalation-job to completion will return back to the parent LOAN_APPLICATION job.
Once an escalator’s escalated node is completed, the escalator will be removed from the outstanding escalators list.
Testing error handling
If an error occurs during stepping and an error process has been configured, the test stepper will automatically step into the error process in exactly the same way as it would step into any other sub process. The In process breadcrumbs will indicate the nesting of jobs currently being run, for example, LOAN_APPLICATION -> ERROR_HANDLER.
Key of Node States
The state of the nodes in the process diagram may be indicated on the diagram by the following icons:
![]() Currently running
Currently running
![]() Completed
Completed
![]() Unassigned
Unassigned
![]() Assigned
Assigned
![]() Paused
Paused
![]() Cancelled
Cancelled
![]() Skipped
Skipped
![]() Failed
Failed
Hovering over any node in the diagram will also display a tool-tip showing all the node’s attributes including the runtime priority and assignment.
Activities
Viewing an
existing activity
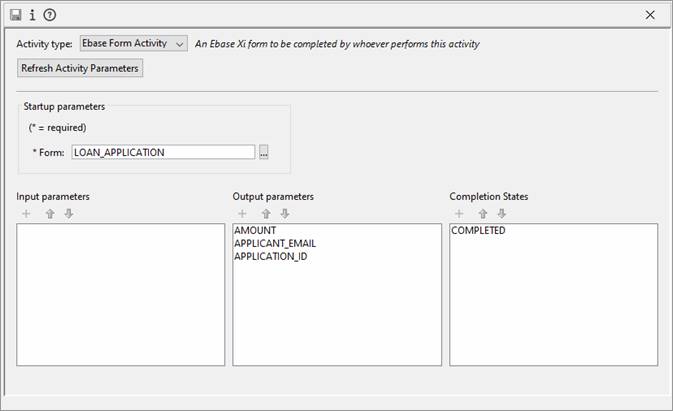
An existing activity can be opened by double clicking on the activity name in the tree panel on the left-hand side of the Ebase Xi designer. This will display the activity editors as follows:
Interactive activity editor
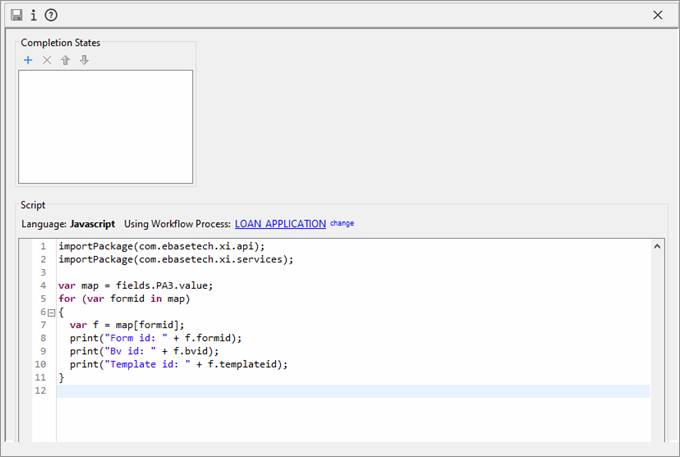
System activity editor
Creating a
new activity
To create a new Interactive Activity, right click in the tree and select New > Workflow > Interactive Activity.
This will display a new interactive activity editor as shown above.
To create a new System Activity, right click in the tree and select New > Workflow > System Activity.
This will display a new system activity editor as shown above.
Configuring an interactive activity
The first thing to select when configuring an interactive activity is the activity type. Types offered by default with the workflow system are Ebase Form Activity, Manual Activity and Custom Activity as described in Activities.
Depending on the activity type selected, the rest of the activity dialog will change to reflect the startup parameters as defined in the activity type. For more details on creating new activity types, see Workflow Customization. Values should be provided for all startup parameters indicated as mandatory.
If the activity will require input or output parameters, these should be added to the lists at the bottom of the dialog.
At least one completion state should also be provided. This will potentially be offered to the user when the interactive activity is executed. The completion state will either be selected implicitly by the application providing the interactive activity or will be selected explicitly by the user in the case of a manual activity.
Configuring a system activity
The main thing to be configured on a system activity is the script code which can be coded using any supported server-side language - this defines what the activity does. Process attributes should be used explicitly in system activity scripts so care should be taken to ensure that the process attributes referred to are actually present in the process in which this activity will be used. Completion states may also be defined. These can be set by the script on the $COMPLETION_STATE system variable and may be referred to in subsequent process steps.